Por Fernanda Alves de Souza* e Caio Huais
Antes de desenhar uma solução de monitoramento de condição, é necessário definir uma ferramenta ou conjunto de ferramentas capazes de possibilitar a convergência IT-OT, através dos 5 pontos listados a seguir.
O advento da Indústria 4.0 traz entre seus pilares, a internet das coisas, o big data, o processamento em nuvem e a inteligência artificial. A coleta de dados de dados aliada ao aumento da capacidade de armazenamento e processamento, permite que modelos e algoritmos de aprendizado de máquina se tornem cada vez mais populares em um contexto industrial.
O Cross Industry Standard Process for Data Mining, CRISP-DM, representado na Figura 5, pode ser definido como uma metodologia recorrente entre Cientistas de Dados para análise de dados.
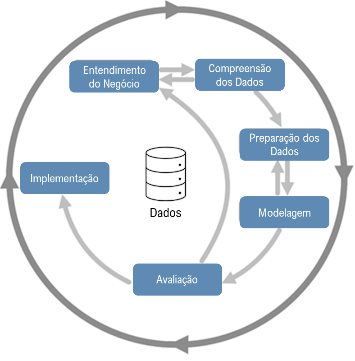
Figura 5 – Metodologia CRISP-DM
A implementação de uma solução CBM deve ser encarada como um processo de melhoria contínua e não um projeto de curto prazo. É possível estabelecer um paralelo ao ciclo PDCA e à metodologia CRISP-DM, sendo as etapas de Entendimento do Negócio, Compreensão dos Dados e Preparação dos Dados relacionadas à fase de Planejar; Modelagem relacionada à Fazer; Avaliação relacionada à Verificar e Implementação relacionada a ajustar. Deste modo, mesmo que exista um volume limitado de informações referentes ao ativo, é possível iniciar um projeto de CBM, pois este será refinado e o modelo será retreinado.
O processo de CBM inicia-se com o monitoramento de parâmetros específicos de ativos; considerando a avaliação desses parâmetros em relação a seus limites e tendências. A conclusão deste processo está na integração da solução a uma ferramenta de gerenciamento de manutenção, como um CMMS, Computerized Maintenance Management System.
A Figura 6 ilustra o fluxo de dados em tempo real, oriundos tanto dos sensores em campo, armazenados em um hiostoriador, quanto das atividades de manutenção executadas, planos de manutenção vigentes e do FMEA, Failure Modes and Effect Analysis. O processo de monitoramento do ativo evolui à medida que novos dados são coletados e percepções de especialistas são aplicadas ao modelo.
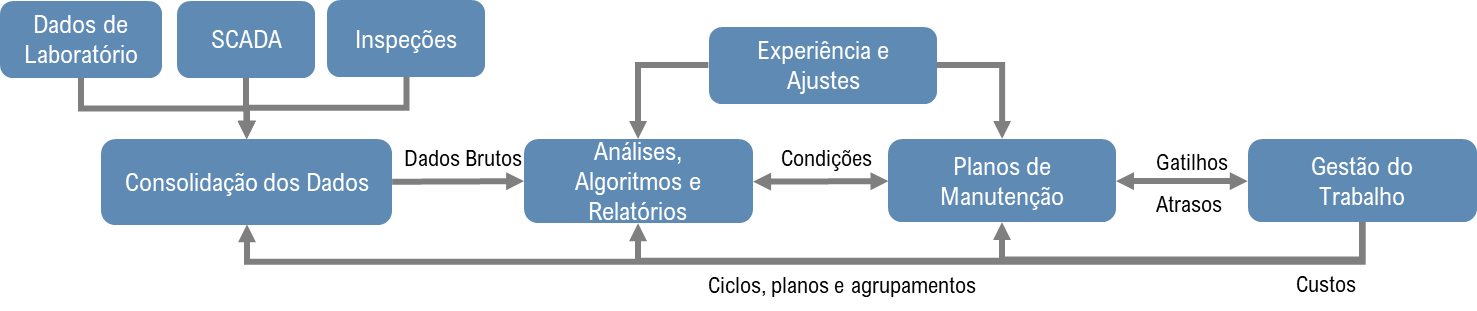
Figura 6 – Fluxo de Informações
Para a implementação de um monitoramento baseado em condição, é necessária a aplicação dos passos descritos a seguir.
Os critérios de escolha de um piloto convergem para uma análise de custo/benefício, levando em consideração a representatividade do ativo nos custos totais de manutenção, os custos adicionais do impacto no negócio e outros impactos (tais como ambientais, saúde e segurança) para uma avaliação completa do retorno financeiro. Nesse processo de escolha, os seguintes aspectos devem ser abordados:
A resposta a estes questionamentos permitirá a equipe avaliar em uma matriz de impacto e esforço, qual equipamento candidato apresenta maior viabilidade e deverá ser o escolhido.
É importante salientar a necessidade de equilibrar o retorno sobre o investimento, a complexidade do projeto e o impacto nos indicadores de produtividade e disponibilidade da companhia.
Após a definição do piloto, o processo de preparação e coleta das informações do ativo é iniciado. Alguns dados que tornarão o processo mais rápido e assertivo são listados a seguir.
Após a coleta, limpeza e organização dos dados, é necessário permitir que os dados falem por si. Estatísticas descritivas, correlações entre as variáveis e eventos conhecidos podem servir de um ponto de partida para compreender o comportamento do ativo.
Nesta etapa é interessante avaliar se o funcionamento do equipamento pode ser descrito através de modelos baseados em formulação física, ou uma abordagem através algoritmos de reconhecimento de padrões é mais recomendada. Uma combinação de técnicas também poderá ser utilizada, a escolha será influenciada pelas percepções observadas na etapa de análise e exploração dos dados.
A Figura 7 representa um esquemático de diferentes técnicas e abordagens para a construção de um modelo para diagnóstico e detecção de anomalias.
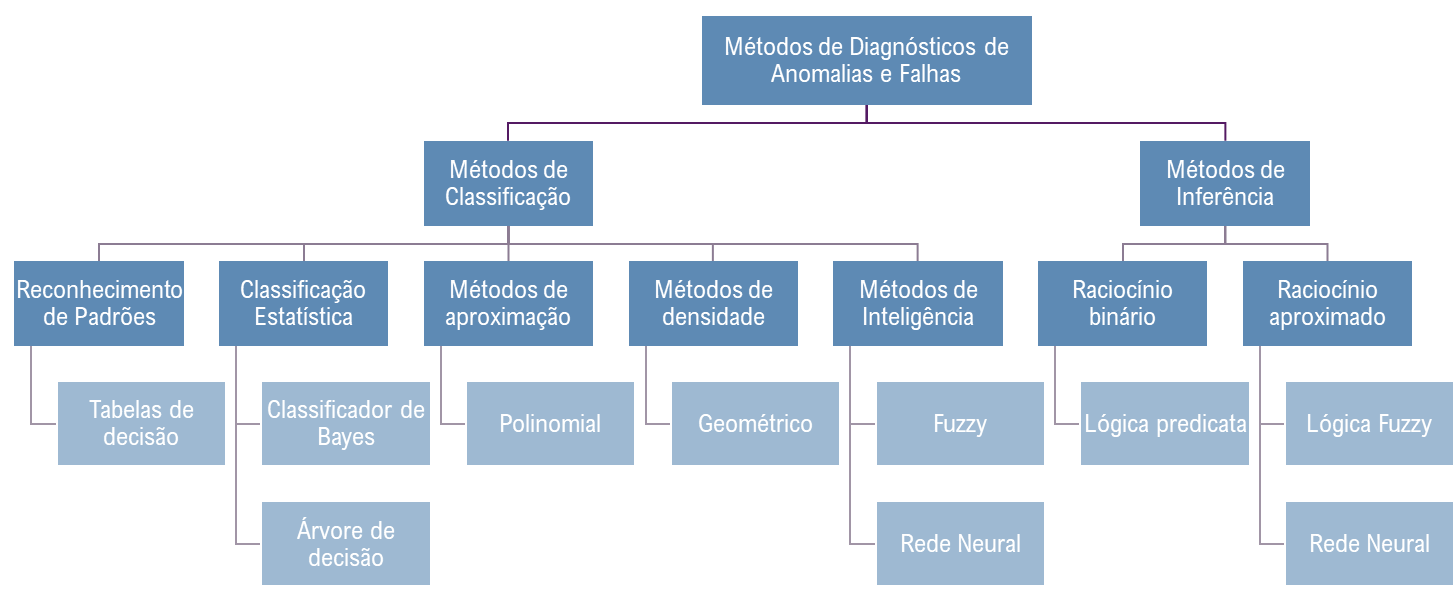
Figura 7 – Exemplos de Métodos para Detecção de Anomalias
Reserve um percentual dos dados para treinamento e a segunda parte para validação dos dados. Compare os resultados previstos aos eventos observados e estabeleça um nível de acurácia.
Também é necessário observar se os cenários de underfititng ou um overfitting, conforme Figura 8, estão acontecendo no modelo. O desempenho não será satisfatório em nenhum destes cenários.
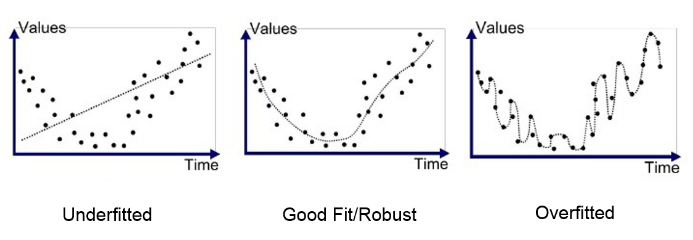
Figura 8 – Underfiting x Overfiting
À medida que novos dados são gerados, somada à deterioração natural de todo ativo, o modelo necessitará de ajustes de modo a garantir a acurácia desejada.
Os planos de manutenção baseados no calendário poderão ser substituídos por planos a evento, cuja regra estará relacionada ao resultado dos algoritmos para detecção de anomalias, gerando automaticamente a ordem de serviço. Neste contexto, o sistema funcionará de modo prescritivo: detectando a falha e, em sequência, a ação corretiva a ser executada.
Sobre os autores:
Caio Huais é engenheiro industrial, especialista em Engenharia Elétrica e Automação com MBA em engenharia de manutenção e gestão de negócios. Atualmente, ocupa posição de gerente corporativo de manutenção no Grupo Equatorial, respondendo pelo desempenho da Alta Tensão de 7 concessionárias do Brasil.
*Fernanda Alves de Souza é Consultora em Confiabilidade e Smart Operations – Alvarez & Marsal. Msc. Engenharia Elétrica -UFMG





